![[파이썬 기본 4] 머신러닝 필수 라이브러리 :: 판다스 총정리](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FcyPu13%2Fbtsv92fpyfE%2FAAAAAAAAAAAAAAAAAAAAALiqJwlJPvcqCVj7_QT1G0YLYPCaf0RgUyJlMRSEGHyF%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1772290799%26allow_ip%3D%26allow_referer%3D%26signature%3DVpGAnH3bb9xRFox94%252F%252FL25AQWZI%253D)
[파이썬 기본 4] 머신러닝 필수 라이브러리 :: 판다스 총정리

머신러닝/인공지능/데이터분석에 들어가기 앞서, 공통적으로 사용되는 파이썬에 대해 계속 연재를 진행중이다.
<이전글>
[파이썬 기본 3] 머신러닝 필수 라이브러리 :: 넘파이
[파이썬 기본 2] 조건문(If문/else문/elif문), 반복문(while문/for문)
[파이썬 기본 1-2] 자료형(문자열/콜렉션), 함수 정의
[파이썬 기본 1-1] 초기 세팅 및 변수, 연산자, sep, input, 형변환, eval()
2. 판다스(Pandas)
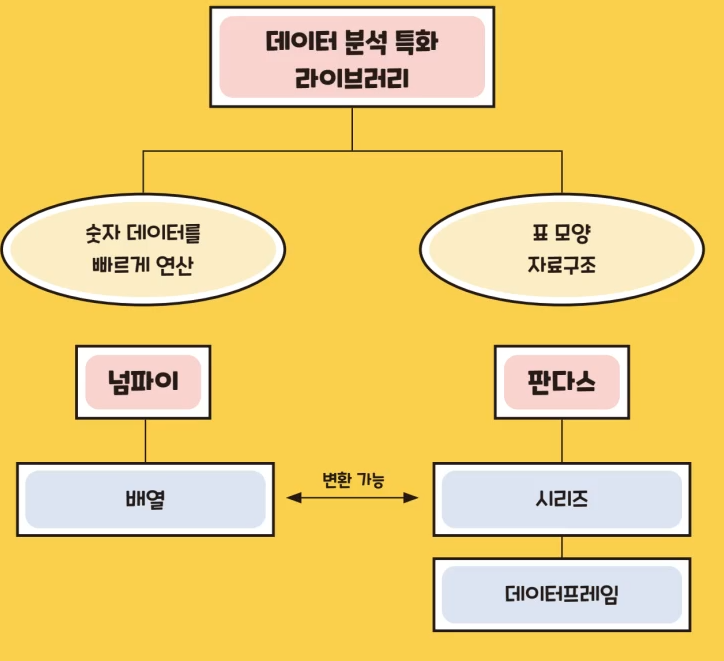
• 2차원 데이터 처리를 넘파이보다 더 빠르고 효율적으로 처리 가능
<명령어 요약>
변수 = pdSeries[1, 2, 3, 4] : [1, 2, 3, 4] 시리즈를 생성하여 변수에 저장 (대문자 주의!)
변수 = pd.Series([1,2,3], index=['a','b','c']) : [1,2,3] 시리즈를 생성하고, 인덱스를 각각 a,b,c로 지정하는 변수 저장 (대문자 주의!)
변수 = pd.DataFrame(a, column=b) : 리스트 a로 행을 만들고 열 이름은 b로 하는 데이터프레임을 생성
변수 = pd.concat([series1, series2, series3, series4], axis=1) : 여러개의 시리즈를 붙여 데이터프레임 생성 후 변수에 저장
변수.columns = ['이름', '성별', '나이', '키'] : 변수의 열 이름 정의
*_df.info() : DataFrame을 구성하고 있는 데이터셋의 칼럼의 정보를 간략히 보여줌
df.to_csv(' 파일경로/파일명.csv ', header=True, index=False, encoding='utf-8') : 데이터프레임 .csv파일로 저장. 헤더(열이름)도 같이 저장하고, 인덱스(순번)은 따로 저장하지 않음. 인코딩 양식은 한글이 있으므로 utf-8로 저장함.
변수 = pd.read_csv('파일경로/파일명.csv', sep=',') : 파일 불러오기. 변수에 엑셀자료를 DataFrame형태로 저장, 이때 데이터프레임을 구분짓는 구분자는 ','로 한다. (csv 파일은 기본 구분자가 쉼표(,)이다. 쉼표를 구분자로 설정하지 않으면 에러남)
from google.colab import drive : 구글 드라이브 사용을 위한 라이브러리 Import
drive.mount('/content/drive') : 구글 드라이브를 마운트 시킴
from google.colab import files : 파일 다운을 위한 라이브러리 Import
files.download('/content/drive/My Drive/file.csv') : 구글 드라이브에 파일을 PC로 다운로드
*_df : 데이터프레임 출력
*_df.head(3) : 데이터프레임의 앞 3줄만 출력(팬시하게 출력)
*_df.tail(3) : 데이터프레임의 끝 3줄만 출력(팬시하게 출력)
type(*_df) : 데이터프레임의 타입 확인
*_df.columns : 데이터프레임의 열 정보 확인
*_df.shape : 데이터프레임의 n행 m열 출력
*_df.info() : 데이터프레임의 행렬 상세 정보 출력
*_df.describe() : 데이터프레임의 각 열별 통계정보 출력
*.value_counts() : Series/DataFrame의 값의 유형과 갯수를 집계해줌
변수 = pd.DataFrame(list명, colums=칼럼명) :: 특정 칼럼명으로 특정 list들을 다중칼럼 자료형인 DataFrame으로 변환변수 = pd.DataFrame(ndarray명, colums=칼럼명) :: 특정 칼럼명으로 특정 ndarray들을 다중칼럼 자료형인 DataFrame으로 변환
변수 = pd.DataFrame(dict) : 딕셔너리 dict로 DataFrame 변환
변수명 = DataFrame명.values : 데이터프레임 값들을 넘파이 ndarray로 변환하여 저장함
변수명 = DataFrame명.values.tolist() : 데이터프레임 값들을 리스트로 변환하여 저장함
변수명 = DataFrame명.to_dict('딕셔너리포맷') : 데이터프레임 값들을 설정한 포맷으로 딕셔너리로 변환하여 저장함
*_df['칼럼명'] = 0 : 칼럼 삽입 후 0 값으로 할당
*_df.replace(딕셔너리) : 딕셔너리에 해당되는 값으로 변경(코드화 할 때 유용함)
*_df.rename(columns={'A':'B'}, inplace=True) : 열 이름을 A에서 B로 변경하고 원본객체에 적용
변수=pd.merge(A, B) : 데이터프레임과 A와 B를 합친 데이터프레임을 변수에 저장
*_df.drop( ['칼럼명'] , axis=0/1, index=None, columns=None, level=None, inplace=False, errors=‘raise’) : 데이터 삭제
*_df.drop( ['칼럼명'] , axis=0/1, inplace=False) : 데이터 삭제 (심플 버전)
변수 = *_df.index : *_df 데이터프레임에 인덱스(순번)을 변수에 저장
print(변수.values) : 변수에 저장된 인덱스(순번)을 출력 (단순하게 print(변수)로 하면 인덱스 기본 정보만 보임)
변수 = *_df['컬럼명'] : *_df 데이터프레임에 특정 컬럼을 시리즈 객체로 저장
변수_df = *_df.reset_index(inplace=False) : 인덱스가 훼손된 경우, 인덱스을 다시 발번 후 변수_df에 저장(원본 객체는 수정X)
변수_df = *_df.reset_index(inplace=True) : 인덱스가 훼손된 경우, 인덱스을 다시 발번(원본 객체는 수정O). 변수_df 대입연산 없이 단독으로도 사용 가능
변수_df = *_df.reset_index(inplace=False, drop=True) : drop=True인 경우, 기존 인덱스가 2번째 열에 추가되지 않음
변수_df = *_df.reset_index('이름', inplace=True, drop=True) : 이름을 인덱스로 쓰고 원본 객체도 수정.
변수=*_df['열이름', '열이름2' ....] : *_df 데이터프레임에서 특정 열들을 뽑아 변수에 저장
변수=*_df['열이름' == 3] : *_df 데이터프레임에서 특정 열의 값이 3인 셀들을 변수에 저장
변수=*_df[*_df['Age'] > 60] : *_df 데이터프레임에서 Age가 60세 이상인 행들을 변수에 저장
변수=*_df['Age' > 60][[ 'Name', 'Age']] : *_df 데이터프레임에서 Age가 60세 이상인 Name, Age 열들을 변수에 저장
*_df.iloc[행번호,열번호] : (위치기반 인덱싱) *_df 데이터프레임에서 특정 행/열의 값을 출력
*_df.loc[행이름,열이름] : (이름기반 인덱싱) *_df 데이터프레임에서 특정 행/열의 값을 출력
변수=*_df[df['나이'].isin([21, 23])] : 나이가 21세, 23세인 행들을 변수에 저장
df[df['이름'].str.contains('봄')] : 이름에 '봄'이 들어가는 경우 출력
df[df['이름'].str.contains('^봄')] : 이름이 '봄'으로 시작하는 경우 출력
df[df['이름'].str.contains('봄$')] : 이름이 '봄'으로 끝나는 경우 출력
df[df['이름'].str.contains('^.{1}봄')] : 이름의 두 번째 글자가 '봄'인 경우 출력
df.sort_index(axis=0).head( ) : 인덱스 순번 기준으로 오름차순 정렬
변수=*_df.sort_values(by=['열이름'], ascending=True, inplace=False) : 특정 열이름 기준으로 오름차순 정렬하고 원본객체는 수정하지 않음
asending 옵션 : True(기본값, 오름차순 정렬) / False(내림차순 정렬)
inplace 옵션 : False(기본값, 원본객체 수정X) / True (원본객체 수정O)
*_df.min() : *_df 데이터프레임의 각 열당 최소값 리턴
*_df.max() : *_df 데이터프레임의 각 열당 최대값 리턴
*_df.sum() : *_df 데이터프레임의 각 열당 합계 리턴
*_df.count() : *_df 데이터프레임의 각 열당 셀 개수 리턴
*_df.mean() : *_df 데이터프레임의 각 열당 평균값 리턴
*_df.std() : *_df 데이터프레임의 각 열당 표준편차 리턴
*_df.median() : *_df 데이터프레임의 각 열당 중간값 리턴
*_df.agg({'max', 'min', 'median'...}) : *_df 데이터프레임의 각 열당 max, min 등 여러 값들을 출력
*_df.agg({'A':'max', 'B':'min', 'C':'median'...}) : *_df 데이터프레임의 A열은 max, B열은 min 등 딕셔너리포맷으로 각각 다른 값들을 출력
변수=*_df.groupby(by='컬럼명').통계함수() : *_df 데이터프레임의 특정 컬럼의 값들을 그룹화하여 '행'으로 표현하여 변수에 대입
변수=*_df.groupby(by=['물건'], as_index=False)['가격'].통계함수() : *_df 데이터프레임의 물건 별 가격을 '열'로 표현하여 변수에 대입 (as_index=False는 인덱스 발번한다는 뜻이고, True는 발번 X)
*_df.isna() : *_df 데이터프레임의 NaN 여부 확인 (True인 경우, NaN값 존재)
*_df.isna().sum() : *_df 데이터프레임의 NaN 개수 출력
*_df.isna() : *_df 데이터프레임의 NaN 여부 확인 (True인 경우, NaN값 존재)
*_df ['열이름_a'] = *_df['열이름'].fillna('~~~') : *_df 데이터프레임의 특정 열의 NaN이 존재하는 경우, 맨 마지막 열에 열이름_a를 추가하여 NaN→~~~로 변경한 열 추가
*_df ['열이름'] = *_df['열이름'].fillna('~~~') : *_df 데이터프레임의 특정 열의 NaN이 존재하는 경우, 해당 열의 NaN→~~~로 값 변경
*_df['열이름'].fillna('~~~', inplace=True) : *_df 데이터프레임의 특정 열의 NaN이 존재하는 경우, 해당 열의 NaN→~~~로 값 변경 ( *_df ['열이름'] = *_df['열이름'].fillna('~~~') 명령어와 동일한 결과 리턴)
변수명= lambda x: 수식
print(변수명(x))
:: 간단한 수식을 람다표현식으로 함수 생성 후, 그 결과를 출력
list(map(lambda x: 수식, [리스트 값])) : 리스트 값에 람다표현식으로 생성한 함수를 모두 적용
*_df['열이름_a']=*_df['열이름'].apply(lambda x: 수식) : *_df 데이터프레임에 특정 열의 값을 람다표현식의 함수를 적용하여 나온 값들을 마지막 열(열이름_a)에 저장
*_df['열이름_a']=*_df['열이름'].apply(lambda x: 'A' if x>5 else 'B') : *_df 데이터프레임에 특정 열의 값을 5보다 크면 A, 작으면 B로 리턴하여 마지막 열(열이름_a)에 저장
① import pandas as pd 명령으로 Pandas라이브러리를 pd에다 정의한다. pd는 판다스를 뜻하는 변수명의 관례이다.
② 변수명 = pd.*() 명령으로 특정 변수를 판다스 데이터로 정의한다.
준비물) law 데이터 취득하기 in 캐글(Kaggle)
1) 로그인
캐글(Kaggle) 캐글(Kaggdle)

2) 스크롤을 내려서 다운로드 아이콘 클릭

1) 시리즈 & 데이터프레임 생성
변수 = pdSeries[1, 2, 3, 4] : [1, 2, 3, 4] 시리즈를 생성하여 변수에 저장 (대문자 주의!)
변수 = pd.Series([1,2,3], index=['a','b','c']) : [1,2,3] 시리즈를 생성하고, 인덱스를 각각 a,b,c로 지정하는 변수 저장 (대문자 주의!)
변수 = pd.DataFrame(a, column=b) : 리스트 a로 행을 만들고 열 이름은 b로 하는 데이터프레임을 생성
변수 = pd.concat([series1, series2, series3, series4], axis=1) : 여러개의 시리즈를 붙여 데이터프레임 생성 후 변수에 저장
변수.columns = ['이름', '성별', '나이', '키'] : 변수의 열 이름 정의
*_df.info() : DataFrame을 구성하고 있는 데이터셋의 칼럼의 정보를 간략히 보여줌
<예시1> - 시리즈 생성
(L4) : [1,2,3,4]를 원소로 갖는 시리즈를 생성하여 a에 저장 (시리즈 a는 인덱스를 지정하지 않았으므로 기본 인덱스로 숫자 0, 1, 2, 3이 지정됨.)
(L6) : [1,2,3]를 원소로 갖는 시리즈를 생성하고 인덱스는 각각 a,b,c로 지정하여 b에 저장

<예시2> - 데이터프레임 생성
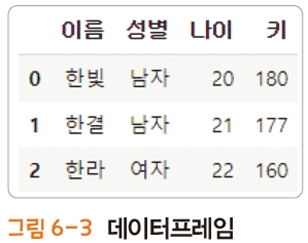
(L6) list1을 행 성분, col_names를 열 이름으로 하는 데이터 프레임 생성

<예시3> - 시리즈를 합쳐 데이터프레임 생성
(L3~6) 각각 열 성분의 시리즈를 생성
(L9~10) 열 성분의 시리즈를 이어붙여 데이터프레임을 생성하고, 이를 변수 data에 저장하며, 열이름 지정
(L11) 변수 data의 타입은 데이터프레임인 것을 확인할 수 있음. 시리즈를 concat(이어붙이기)하는 순간 데이터프레임이 된다.
(L12) 데이터 확인
(L13) 이미 정의되어있는 데이터프레임을 다시 데이터프레임 정의하는 명령어를 쓰게되는 경우, 팬시하게 출력하는 기능밖에 없음

※ 보통, 시리즈를 묶어서 데이터프레임을 만들기보단 리스트나 딕셔너리를 이용하여 데이터프레임을 정의한다.
<예시4> - 딕셔너리로 데이터프레임 생성

<예시5> - 넘파이배열(ndarray)로 데이터프레임 생성

2) .csv 파일 저장/불러오기
df.to_csv(' 파일경로/파일명.csv ', header=True, index=False, encoding='utf-8') : 데이터프레임 .csv파일로 저장. 헤더(열이름)도 같이 저장하고, 인덱스(순번)은 따로 저장하지 않음. 인코딩 양식은 한글이 있으므로 utf-8로 저장함.
변수 = pd.read_csv('파일경로/파일명.csv', sep=',') : 파일 불러오기. 변수에 엑셀자료를 DataFrame형태로 저장, 이때 데이터프레임을 구분짓는 구분자는 ','로 한다. (csv 파일은 기본 구분자가 쉼표(,)이다. 쉼표를 구분자로 설정하지 않으면 에러남)
from google.colab import drive : 구글 드라이브 사용을 위한 라이브러리 Import
drive.mount('/content/drive') : 구글 드라이브를 마운트 시킴
from google.colab import files : 파일 다운을 위한 라이브러리 Import
files.download('/content/drive/My Drive/file.csv') : 구글 드라이브에 파일을 PC로 다운로드
★주의★
구글 Colab을 개발환경으로 사용하는 경우 : 로컬 PC의 경로를 인식 못함. 구글 Drive에 저장하고 불러들여야 함.
Jupyter를 개발환경으로 사용하는 경우 : 로컬 PC의 경로를 인식함.
★주의★
경로를 입력할때는 백슬래시(\)가 아닌 슬래시(/)로 입력해주어야 한다.
그렇지 않으면 아래와 같은 SyntaxError가 난다.
titanic_df = pd.read_csv('C:\Users\PC\Downloads\titanic\train.csv')
^
SyntaxError: (unicode error) 'unicodeescape' codec can't decode bytes in position 2-3: truncated \UXXXXXXXX escape
★참고★
utf-8로 인코딩을 하게 되면, 소스코드 상에서 .csv 파일을 불러오고, 메모장으로 볼 때는 문제없지만, 엑셀을 켜서 보면 깨져서 나온다. 이런 경우, 메모장으로 저장한 .csv 파일을 실행시켜서 Ctrl+Shift+S로 다른이름으로 저장을 누른 후 ANSI로 인코딩 타입을 바꾸면 엑셀에서 잘 보인다.
당연히 나중에 파이썬에서 불러올때는인코딩을 utf-8로 바꿔줘야 한다.
(ANSI 인코딩 타입은 파이썬에서 가져오지 못함)
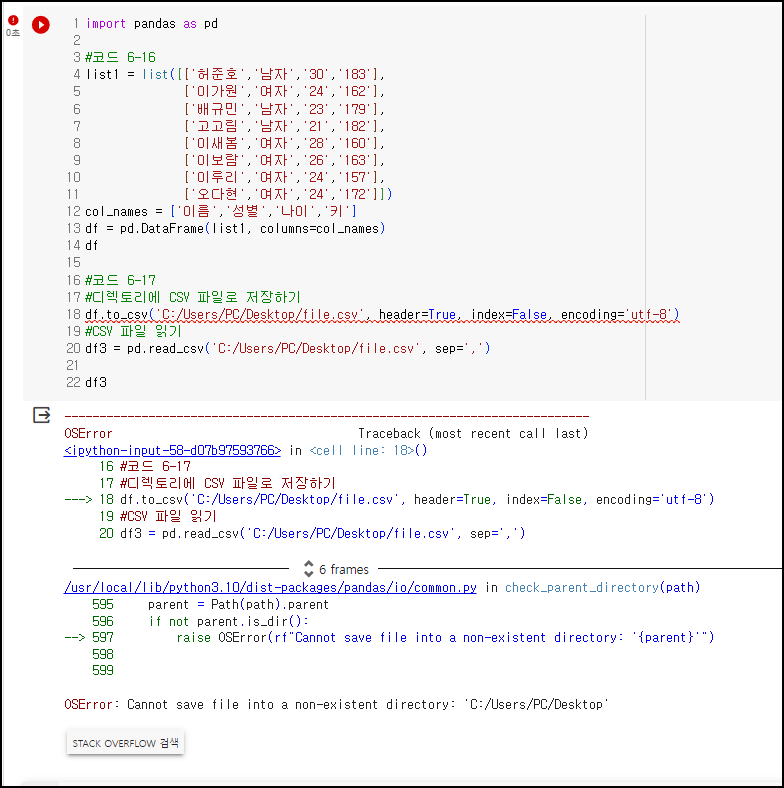
<예시1> - 구글 Colab에서 로컬 PC 경로에 저장/불러오기 (에러 발생)
(L4) 리스트 정의
(L12) 열이름 정의
(L13) 정의한 리스트와 열이름으로 데이터프레임 생성
(L18) 구글 Colab에서는 로컬PC의 경로를 인식하지 못하여 에러 발생
<예시2> - Jupyter Notebook에서 데이터프레임 저장/불러오기
예시1과 완전히 동일한 소스코드지만, 해당 경로에 정상적으로 .csv 파일이 저장되고 잘 불러옴

<예시3> - 구글 Colab 내 드라이브 안에 파일 저장/불러오기
(L3) 구글 드라이브를 Import
(L4) 구글 드라이브 경로를 마운트시킴
(L20) 구글 드라이브-내 드라이브에 file.csv 파일 저장. (옵션 설명은 생략)
(L22) 구글 드라이브-내 드라이브에 file.csv 파일 불러오기

<예시4> - 구글 Colab에 저장된 파일 로컬 PC에 다운로드
(L1) 파일 다운을 위한 라이브러리 Import
(L2) 구글 드라이브에 파일을 PC로 다운로드. (다운로드 경로는 C:\Users\PC\Downloads로 경로 지정은 불가능함)

<예시5>
엑셀을 읽어야 하므로 변수는 DataFrame (칼럼이 여러 개인 데이터 구조체) 형태로 읽어와야 한다.
DataFrame의 경우, 변수뒤에 _df를 붙이는 것이 관례이다.
3) 데이터프레임 속성 확인
*_df : 데이터프레임 출력
*_df.head(3) : 데이터프레임의 앞 3줄만 출력(팬시하게 출력)
*_df.tail(3) : 데이터프레임의 끝 3줄만 출력(팬시하게 출력)
type(*_df) : 데이터프레임의 타입 확인
*_df.columns : 데이터프레임의 열 정보 확인
*_df.shape : 데이터프레임의 n행 m열 출력
*_df.info() : 데이터프레임의 행렬 상세 정보 출력
*_df.describe() : 데이터프레임의 각 열별 통계정보 출력
<예시1> - 각종 정보 출력(1) - 데이터 타입이 문자열인 경우
(코드6-18) 데이터프레임 df의 열정보 출력
(코드6-19) 데이터프레임 df의 각 열별 통계정보 출력 ; count=요소 개수, unique=중복제거했을때 요소 개수, top=빈도수가 제일 많은것(빈도수가 1이면 제일 앞에있는거 출력해줌), freq=빈도수가 제일 많은 것의 빈도수(중복수)
(코드6-20) 데이터프레임 df의 앞 3줄만 출력
(코드6-21) 데이터프레임 df의 뒤 3줄만 출력

<예시2> - 각종 정보 출력(2) 데이터 타입이 숫자인 경우
titanic_df = pd.read_csv('d:/Example/train.csv')
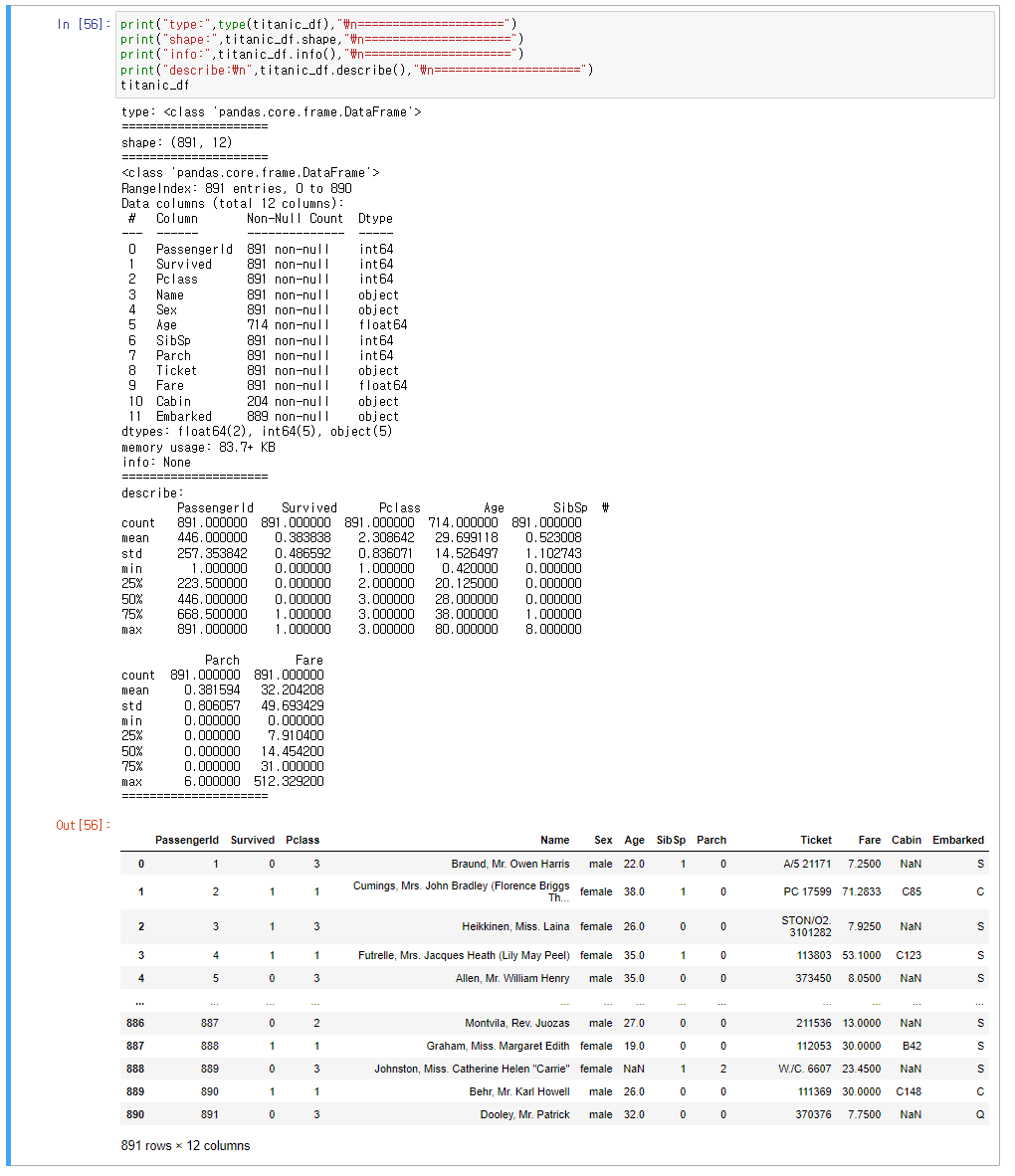
print("type:",type(titanic_df),"\n=====================")
print("shape:",titanic_df.shape,"\n=====================")
print("info:",titanic_df.info(),"\n=====================")
print("describe:\n",titanic_df.describe(),"\n=====================")
titanic_df
<출력결과>
type(*_df) : class 'pandas.core.frame.DataFrame이라고 출력된다.
*_df.shape : 891x12 행렬을 지닌 데이터프레임이다.
*_df.info() : 데이터프레임의 각 행별 정보(자료형 등)를 시현해준다.
*_df.describe() : 데이터프레임의 각 행별 통계정보를 보여준다.
*_df : 데이터프레임에 어떤 데이터가 저장되어있는지 보여준다.
4) 다른 타입으로 데이터 변환
*.value_counts() : Series/DataFrame의 값의 유형과 갯수를 집계해줌
변수 = pd.DataFrame(list명, colums=칼럼명) :: 특정 칼럼명으로 특정 list들을 다중칼럼 자료형인 DataFrame으로 변환변수 = pd.DataFrame(ndarray명, colums=칼럼명) :: 특정 칼럼명으로 특정 ndarray들을 다중칼럼 자료형인 DataFrame으로 변환
변수 = pd.DataFrame(dict) : 딕셔너리 dict로 DataFrame 변환
변수명 = DataFrame명.values : 데이터프레임 값들을 넘파이 ndarray로 변환하여 저장함
변수명 = DataFrame명.values.tolist() : 데이터프레임 값들을 리스트로 변환하여 저장함
변수명 = DataFrame명.to_dict('딕셔너리포맷') : 데이터프레임 값들을 설정한 포맷으로 딕셔너리로 변환하여 저장함
① DataFrame → Series 변환하기

※ 참고

② 1차원 리스트 → DataFrame 변환하기

③ 1차원 ndarray(넘파이행렬) → DataFrame 변환하기

④ n차원 리스트 → DataFrame 변환하기

⑤ n차원 ndarray → DataFrame 변환하기
<예시>

⑥ 딕셔너리 → DataFrame 변환하기
딕셔너리는 단어 그대로 ‘사전’이라는 뜻이다. 즉 "people"이라는 단어에 "사람", "baseball"이라는 단어에 "야구"라는 뜻이 부합되듯이 딕셔너리는 Key와 Value를 한 쌍으로 가지는 자료형이다. 예컨대 Key가 "baseball"이라면 Value는 "야구"가 될 것이다.

딕셔너리는 리스트나 튜플처럼 순차적으로(sequential) 해당 요솟값을 구하지 않고 Key를 통해 Value를 얻는다. 이것이 바로 딕셔너리의 가장 큰 특징이다. baseball이라는 단어의 뜻을 찾기 위해 사전의 내용을 순차적으로 모두 검색하는 것이 아니라 baseball이라는 단어가 있는 곳만 펼쳐 보는 것이다.

⑦ DataFrame → ndarray 변환하기
<예시>
array3에 df_dict 데이터프레임 값들을 *.values를 이용하여 값들을 저장한다. *.values 함수를 이용하면 저장된 array3 변수는 자동으로 넘파이 ndarray로 자료형이 저장된다.

⑧ DataFrame → 리스트 변환하기

⑨ DataFrame → 딕셔너리 변환하기
※ 딕셔너리 포맷의 종류
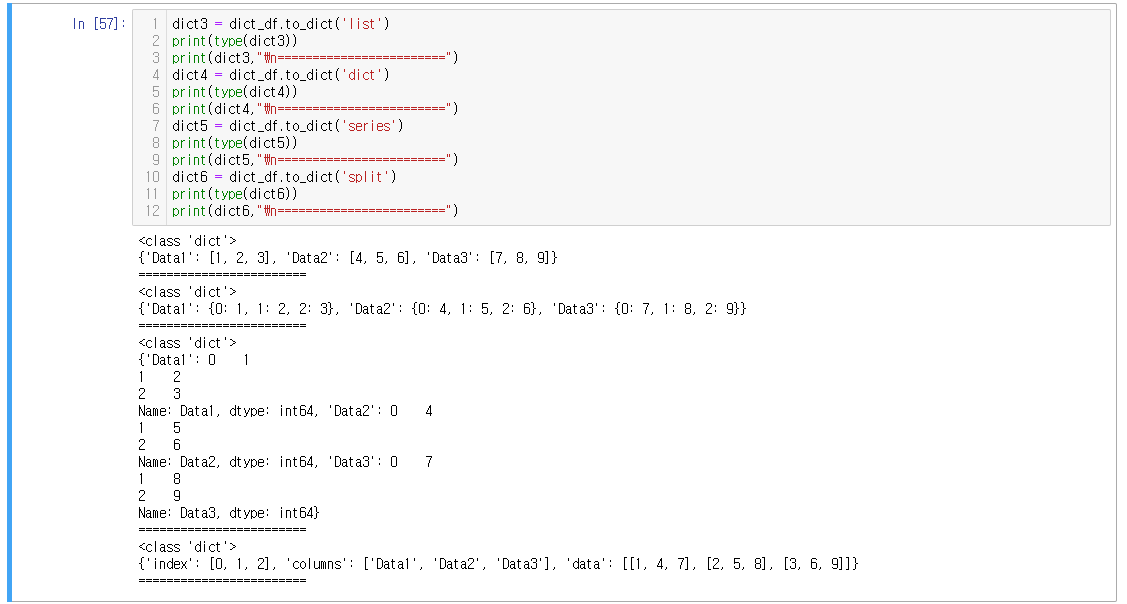
- 'list' (기본값): 열 이름을 키로 사용하고 열 데이터를 리스트로 변환 (키-값 쌍으로 저장됨)
- 'dict': 열 이름을 키로 사용하고 열 데이터를 딕셔너리로 변환 (이중 키-값 쌍으로 저장됨)
- 'series': 열 이름을 키로 사용하고 열 데이터를 Series 객체로 변환 (이중 키-값(시리즈) 쌍으로 저장됨)
- 'split': 열 이름을 기준으로 열 데이터를 딕셔너리로 변환하며, 인덱스를 따로 지정 가능 (인덱스/키/값이 각각 저장됨)
<예시>
5) 컬럼 삽입/변경
*_df['칼럼명'] = 0 : 칼럼 삽입 후 0 값으로 할당
*_df.replace(딕셔너리) : 딕셔너리에 해당되는 값으로 변경(코드화 할 때 유용함)
*_df.rename(columns={'A':'B'}, inplace=True) : 열 이름을 A에서 B로 변경하고 원본객체에 적용
변수=pd.merge(A, B) : 데이터프레임과 A와 B를 합친 데이터프레임을 변수에 저장
<예시1>
titanic_df 마지막 열에 새로운 컬럼 Age_0이 추가고, 0값을 할당한다.

<예시2>
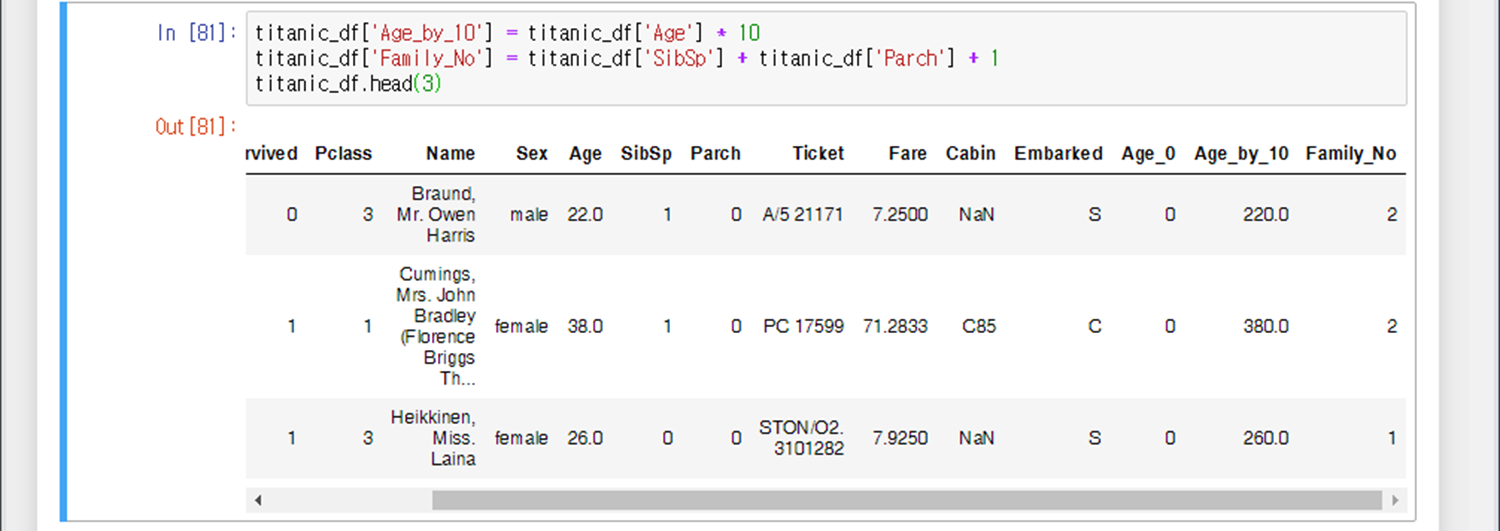
Age_by_10 컬럼을 맨 마지막 열에 추가하고 Age 컬럼x10 값을 대입한다.
Family_No 컬럼을 맨 마지막 열에 추가하고 SibSp 컬럼+ Parch 컬럼 +1 값을 대입한다.
<예시3>
기존에 정의되어있는 Age_by_10 컬럼에 숫자 100 추가

<예시4> - 컬럼 추가
보너스 열을 추가하여 나이 X 10000으로 값을 넣어줌
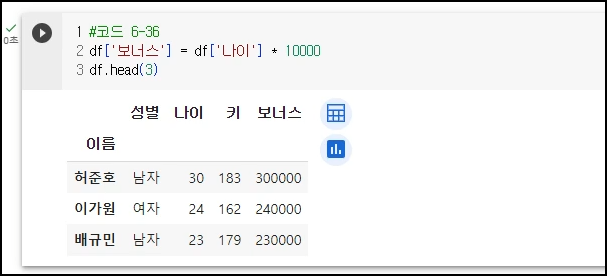
<예시5> - 남자를 1로, 여자를 0으로 코드화하기
(L2) 코드화하기 위해서는 이중 딕셔너리로 정의해야 한다. '성별'에 해당하는 딕셔너리에서, 남자는 1, 여자는 0으로 이중 딕셔너리 정의
(L3) 정의된 rep_cond 이중딕셔너리에 대응되는 행/열 값 변경
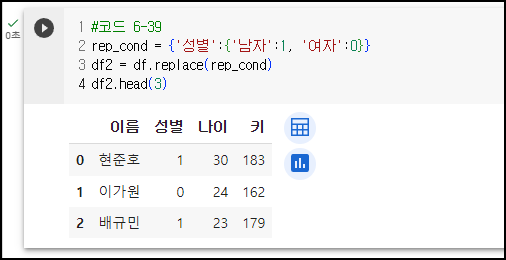
<예시6> - 컬럼 이름 바꾸기
열 이름을 키에서 키 평균으로 변경 (이번만 변경한 것이지, 원본객체는 적용되지 않는다.)

<예제7> - 컬럼 이름 바꾸고 컬럼 합치기 (원본객체 미적용)
(L1~2) mean_by_gender 데이터프레임의 컬럼 이름을 '키'에서 '키 평균'으로 변경 (원본객체 미적용)
(L4~5) std_by_gender 데이터프레임의 컬럼 이름을 '키'에서 '키 표준편차'으로 변경 (원본객체 미적용)
(L7~8) 데이터프레임 mean_by_gender과 std_by_gender의 컬럼을 합치기. 하지만, L1~5에서 컬럼 이름 변경작업이 원본객체 변경을 일으키지 않았으므로, 컬럼 이름이 '키'로 둘다 같아짐에 따라 혼선이 생겨 값이 출력되지 않았다.
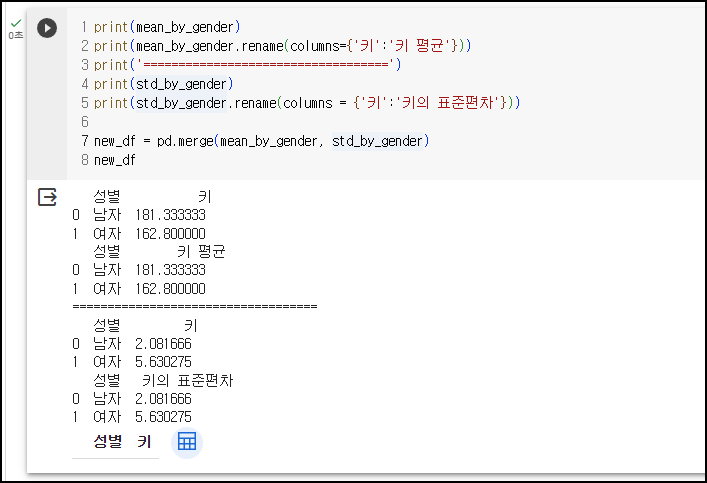
<예제8> - 컬럼 이름 바꾸고 컬럼 합치기 (원본객체 적용)
(L1~2) mean_by_gender 데이터프레임의 컬럼 이름을 '키'에서 '키 평균'으로 변경 (원본객체 적용)
(L4~5) std_by_gender 데이터프레임의 컬럼 이름을 '키'에서 '키 표준편차'으로 변경 (원본객체 적용)
(L7~8) 데이터프레임 mean_by_gender과 std_by_gender의 컬럼을 합치기. L1~5에서 컬럼 이름 변경작업이 원본객체에도 적용됨에 따라, 정상 출력 됨.

6) 컬럼 삭제
컬럼 삭제 함수인 *,drop은 다양한 옵션을 가지고 있다. 그 중 주요하게 들어가야 할 옵션은 label(삭제하고자 하는 행렬), axis(행/열 지정), inplace(원본삭제여부)이다.

inplace=False 이면 원본 손실 없이 원본을 복제하여 칼럼 삭제한다. inplace=True 인 경우에는 원본 칼럼이 삭제된다. inplace 옵션이 생략된 경우, False가 기본값이다.
<예시1>
원본 데이터 프레임(titanic_df)에서 'Age_0' 열을 삭제하고 그 결과를 drop_df에 저장한다. (inplace 옵션이 생략되었으므로 원본 데이터 프레임에서는 삭제하지 않는다.)


<예시2>
원본 데이터 프레임(titanic_df)에서 ['Age_0', 'Age_by_10', 'Family_No'] 열을 모두 삭제한다.
inplace가 True으로 원본 데이터 프레임의 열 삭제가 목적이므로 drop_df에 별도 저장없이 None이 반환된다.

<예시3>
원본 데이터 프레임(titanic_df)에서 0~2 행을 모두 삭제한다.
inplace가 True인 경우, 예시2처럼 변수에 대입하는 방법 외에 *.drop 명령어만 단독으로 실행해도 된다.
(inplace=False인 경우는 반드시 변수 대입해주는 포맷으로 써야함)
★주의★
0~2행을 지우고 싶어서 [:2]라고 하면 구문오류가 난다.
[0,1,2]는 괜찮지만, [:2]를 사용하는 대신 range(2)라고 사용해야 구문오류가 안난다.

<예시4> - 보너스 열 삭제(원본객체 적용)

7) 인덱스 객체 / 시리즈 객체 / 인덱스 리셋
변수 = *_df.index : *_df 데이터프레임에 인덱스(순번)을 변수에 저장
print(변수.values) : 변수에 저장된 인덱스(순번)을 출력 (단순하게 print(변수)로 하면 인덱스 기본 정보만 보임)
변수 = *_df['컬럼명'] : *_df 데이터프레임에 특정 컬럼을 시리즈 객체로 저장
변수_df = *_df.reset_index(inplace=False) : 인덱스가 훼손된 경우, 인덱스을 다시 발번 후 변수_df에 저장(원본 객체는 수정X)
변수_df = *_df.reset_index(inplace=True) : 인덱스가 훼손된 경우, 인덱스을 다시 발번(원본 객체는 수정O). 변수_df 대입연산 없이 단독으로도 사용 가능
변수_df = *_df.reset_index(inplace=False, drop=True) : drop=True인 경우, 기존 인덱스가 2번째 열에 추가되지 않음
변수_df = *_df.reset_index('이름', inplace=True, drop=True) : 이름을 인덱스로 쓰고 원본 객체도 수정.
① 인덱스 객체 (*_df.index)
변수 = *_df.index : *_df 데이터프레임에 인덱스(순번)을 변수에 저장
print(변수.values) : 변수에 저장된 인덱스(순번)을 출력 (단순하게 print(변수)로 하면 인덱스 기본 정보만 보임)
<예시1>
(L4) index에 titanic_df의 인덱스를 저장
(L5) print(index)를 통해 index 변수에 저장된 인덱스 정보를 출력
(L6) print(index.values)를 통해 실제 저장된 인덱스 값들을 출력

<예시2>
(L2) index 변수의 타입은 판다스 라이브러리를 사용하여 정의한 RangeIndex라는 녀석이다.
(L3) index.values의 타입은 넘파이 ndarray이다. 실제 저장된 인덱스 값이 저장된 배열이다.
(L4) index.values의 shape은 891개의 값을 가진 1차원 ndarray 배열이다.
(L5~L7) 0~4번째 값을 출력하기 위해서 [:5]는 index뒤에 붙여도 되고, values 뒤에 붙여도 된다. 하지만 값 출력을 위해서는 반드시 .values를 붙여야 한다. .values를 붙이지 않으면 인덱스의 정보만 출력해주게 된다(L5).
(L8~9) 유일하게 단일 값출력을 하는 경우에 한해서, .values를 붙이는 여부와 상관없이 index[7]을 출력해도 출력이 가능하다.
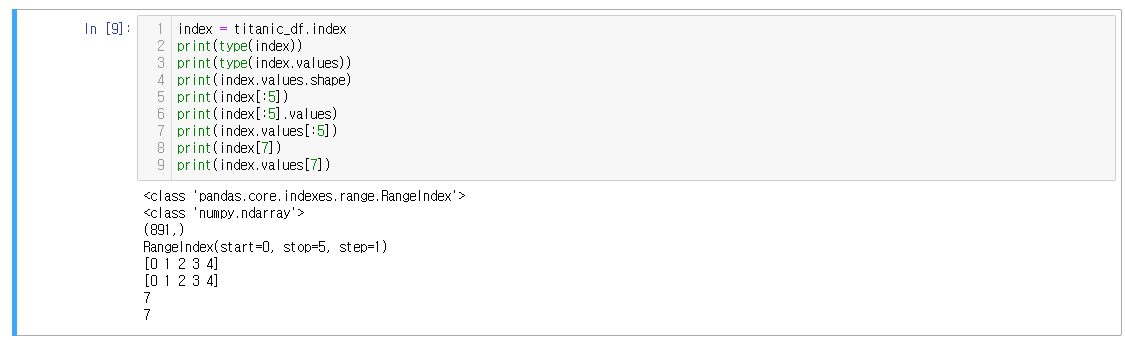
<예시3>
인덱스는 고유한 값이므로 임의로 수정(대입연산)이 불가능하다.

② 시리즈 객체
변수 = *_df['컬럼명'] : *_df 데이터프레임에 특정 컬럼을 시리즈 객체로 저장
<예시1>
데이터프레임의 Fare 컬럼을 series_fair 변수에 저장
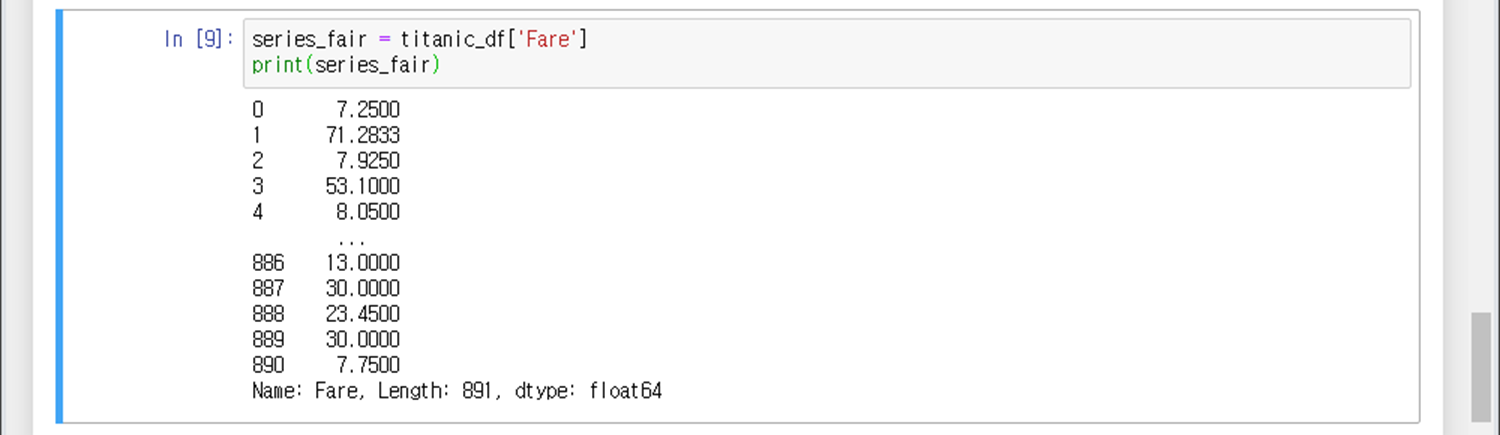
<예시2>
series_fair 변수가 시리즈 객체이므로 다양한 수학연산 함수를 사용할 수 있다.
(L1) *.max() 함수는 시리즈에서 최대값을 구해줌
(L2) *.sum() 함수는 시리즈의 모든 값의 합을 구해줌 (소수점 네 자리까지)
(L3) sum(*) 함수는 시리즈의 모든 값의 합을 구해줌 (소수점 열 두 자리까지)
(L4) 시리즈 모든 값에서 3을 더하고 첫 3행 까지만 출력
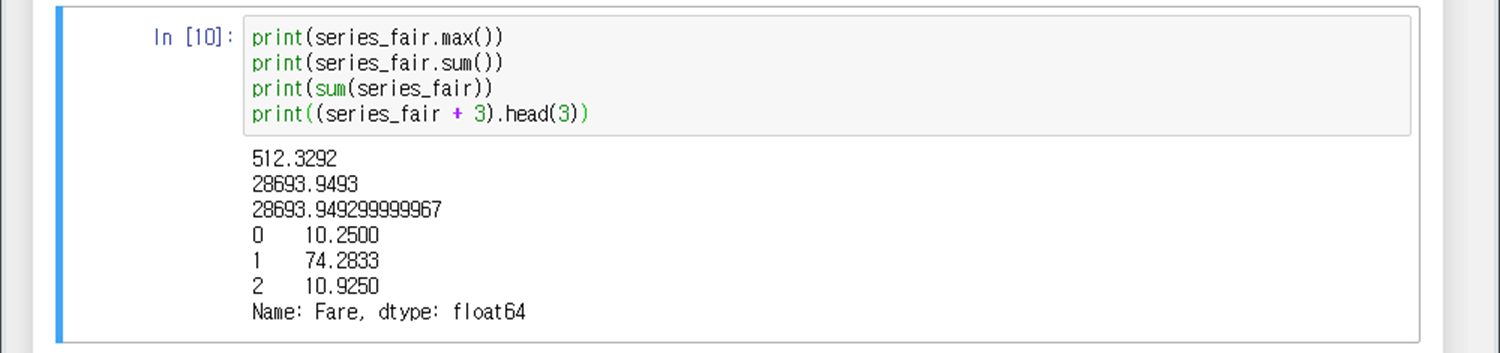
③ 인데스 리셋
변수_df = *_df.reset_index(inplace=False) : 인덱스가 훼손된 경우, 인덱스을 다시 발번 후 변수_df에 저장(원본 객체는 수정X)
변수_df = *_df.reset_index(inplace=True) : 인덱스가 훼손된 경우, 인덱스을 다시 발번(원본 객체는 수정O). 변수_df 대입연산 없이 단독으로도 사용 가능
변수_df = *_df.reset_index(inplace=False, drop=True) : drop=True인 경우, 기존 인덱스가 2번째 열에 추가되지 않음
변수_df = *_df.reset_index('이름', inplace=True, drop=True) : 이름을 인덱스로 쓰고 원본 객체도 수정.
<예시1>
(L3) .csv 파일 로드하여 titanic_df 변수에 저장
(L4) titanic_df 변수에 저장되어있는 0~2행 삭제
(L5) 행 삭제로 인하여 꼬여버린 인덱스를 재생성함 (과거의 인덱스는 1열에 index라는 이름의 칼럼으로 추가됨)
(L6) 당연히 타입은 데이터프레임임
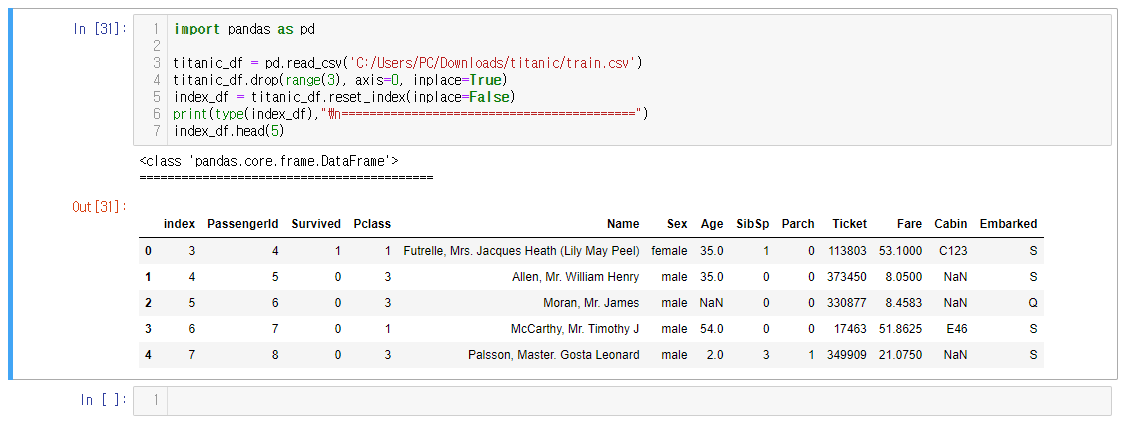
<예시2>
(L1) value_counts 변수에 원본(titanic_df)의 Pclass열을 집계하여 저장함
(L2) 3 > 1 > 2 순으로 많은 개수순으로 정렬된 것이 출력됨
(L3) 1차원의 데이터프레임이므로 자료형은 시리즈임
(L4) 인덱스 리셋 :: 3 > 1 > 2 순으로 저장되어있는 첫번째 열(Pclass에 저장되어있는 값이지만, 파이썬은 이를 인덱스로 인식했다) 대신, 새로운 인덱스 부여
(L6) 이제 차수(Degree)가 2가 되었으므로 자료형은 데이터프레임임

<예시3>
drop 옵션에 의해 기존의 인덱스가 2번째 열에 추가되지 않음

<예시4>
drop 옵션에 의해 기존의 인덱스가 2번째 열에 추가되지 않음

<예시5>
기존의 번호 인덱스를 없애고 이름으로 인덱스를 정의

<예시6>
이름으로 썼던 인덱스 말고 인덱스 순번 다시 발번
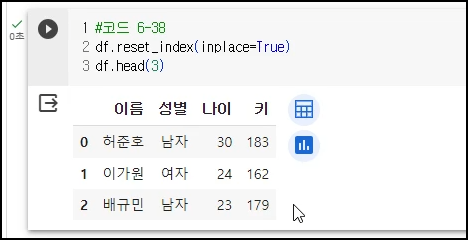
7) 데이터프레임의 특정 열&셀 추출하기
변수=*_df['열이름', '열이름2' ....] : *_df 데이터프레임에서 특정 열들을 뽑아 변수에 저장
변수=*_df['열이름' == 3] : *_df 데이터프레임에서 특정 열의 값이 3인 셀들을 변수에 저장
변수=*_df[*_df['Age'] > 60] : *_df 데이터프레임에서 Age가 60세 이상인 행들을 변수에 저장
변수=*_df['Age' > 60][[ 'Name', 'Age']] : *_df 데이터프레임에서 Age가 60세 이상인 Name, Age 열들을 변수에 저장
*_df.iloc[행번호,열번호] : (위치기반 인덱싱) *_df 데이터프레임에서 특정 행/열의 값을 출력
*_df.loc[행이름,열이름] : (이름기반 인덱싱) *_df 데이터프레임에서 특정 행/열의 값을 출력
변수=*_df[df['나이'].isin([21, 23])] : 나이가 21세, 23세인 행들을 변수에 저장
df[df['이름'].str.contains('봄')] : 이름에 '봄'이 들어가는 경우 출력
df[df['이름'].str.contains('^봄')] : 이름이 '봄'으로 시작하는 경우 출력
df[df['이름'].str.contains('봄$')] : 이름이 '봄'으로 끝나는 경우 출력
df[df['이름'].str.contains('^.{1}봄')] : 이름의 두 번째 글자가 '봄'인 경우 출력
★ 주의 ★
※ 단일 대괄호 [ ]와 이중 대괄호 [[ ]]의 차이
단일 대괄호 []를 사용하면 Series를 반환하고, 이중 대괄호 [[]]를 사용하면 데이터프레임을 반환합니다.
df[['이름', '키']]는 데이터프레임에서 '이름'과 '키' 열을 선택하여 데이터프레임으로 반환합니다. 결과는 데이터프레임입니다.
df['이름', '키']는 데이터프레임에서 '이름'과 '키' 열을 선택하는 것이 아니라, '이름' 열과 '키'라는 레이블로 된 하나의 열을 선택하려는 시도입니다. 이렇게 작성하면 오류가 발생할 것이며, 예를 들어 '이름' 열과 '키'라는 레이블이 없는 경우 KeyError가 발생할 것입니다.
따라서, df[['이름', '키']]를 사용하여 '이름'과 '키' 열을 선택하여 데이터프레임으로 반환해야 합니다.
① 특정 행/열 값 추출하기
변수=*_df['열이름', '열이름2' ....] : *_df 데이터프레임에서 특정 열들을 뽑아 변수에 저장
변수=*_df['열이름' == 3] : *_df 데이터프레임에서 특정 열의 값이 3인 셀들을 변수에 저장
변수=*_df[*_df['Age'] > 60] : *_df 데이터프레임에서 Age가 60세 이상인 행들을 변수에 저장
변수=*_df['Age' > 60][[ 'Name', 'Age']] : *_df 데이터프레임에서 Age가 60세 이상인 Name, Age 열들을 변수에 저장
<예시1> - 이름, 키만 뽑아서 데이터프레임으로 출력
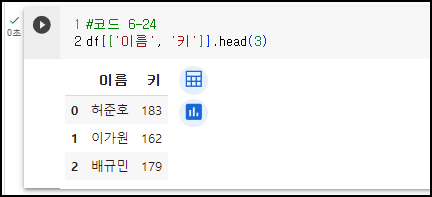
<예시2> - 키가 180 넘는 사람들만 출력 (타입 변환)
키 열만 시리즈[ ] 형태로 추출하고, 이 타입이 str이므로 int 형태로 변경한 뒤, 180이 넘는 경우 각 행을 데이터프레임[[ ]] 형태로 출력

참고로, 기존에 정의한 리스트 및 데이터프레임에는 키와 나이가 문자열(' ')로 정의되어 있었다.

<예시3> - 키가 180 넘는 사람들만 출력 (문자열이 아닌 숫자로 재정의 후)
(L2~11) 예시2와 다르게 나이와 키 부분을 문자열(' ')이 아닌 숫자형태로 지정하여 리스트 재정의 후 데이터프레임을 생성하였다.
(L13) 키 180 이상만 데이터 프레임 [[ ]] 형태로 출력하니 오류없이 잘 된다.

<예시4>
(L1) Pclass열만 뽑아서 시리즈로 3줄만 출력
(L2~3) AA1 변수에 Pclass 열 값을 저장. 이때 1차원 열이므로 타입은 시리즈이다.
(L4) Pclass열과 Survived 열 값만 뽑아서 데이터프레임으로 3줄만 출력
(L5~6) AA2 변수에 Pclass와 Survived 열 값을 저장. 이는 2차원 열이므로 타입은 데이터프레임이다.
※참고
head함수를 쓸때마다 print를 걸어준 이유는, 내가 쓰고있는 IDE인 주피터 노트북 특성상, print로 묶어주지 않으면 마지막 문장(L6)만 출력된다.
L1, L4는 다른 IDE에서는 print없이도 출력된다.

<예시5>
titanic_df 데이터프레임에서 Pclass 열의 값이 3인 행들을 출력

<예시6>
titanic_df 데이터프레임에서 Age가 60세 이상인 행들을 titanic_boolean에 저장. 조건문에 부합하는 경우 True를, 부합하지 않는 경우 False를 리턴하며 True인 것들만 게더링한다는 의미에서 불린 인덱싱이라고 부른다.

<예시7>
titanic_df 데이터프레임에서 Age가 60세 이상인 행들을 Name과 Age 열만 출력한다.

<예시8>
&(AND)나 |(OR) 혹은 ~(NOT) 연산자를 이용하여 조건에 맞는 행을 출력하는 불린인덱싱이 가능하다. 표현방법은 In [70]과 같이 해도 되고 In [71]과 같이 해도 동일하게 출력이 가능하다.

<예시9> - 성별이 여자이면서 키가 160 이상인 행들만 출력

<예시10> - 나이가 28 이상이거나 성별이 남자인 행들만 출력

② 위치/이름기반으로 특정 행/열 값 추출하기
*_df.iloc[행번호,열번호] : (위치기반 인덱싱) *_df 데이터프레임에서 특정 행/열의 값을 출력
*_df.loc[행이름,열이름] : (이름기반 인덱싱) *_df 데이터프레임에서 특정 행/열의 값을 출력
<예시1> - 1~4행, 0~3열 값들을 출력 (위치기반 인덱싱)
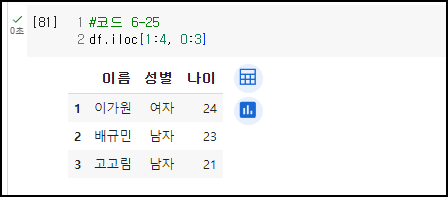
<예시2>
0행을 출력하고 싶어서 해봤으나, 오류난다. (단일 행출력은 어떻게 하는거지?)
이때 필요한 것이 iloc 또는 loc 함수이다.(설명은 후술하겠다.)


<예시3>
0~1행을 출력하고 싶어서 했는데, 이건 된다! (단일 행 출력은 안되지만, 슬라이싱 행 출력은 되나보다. 왜인지는 모른다.)
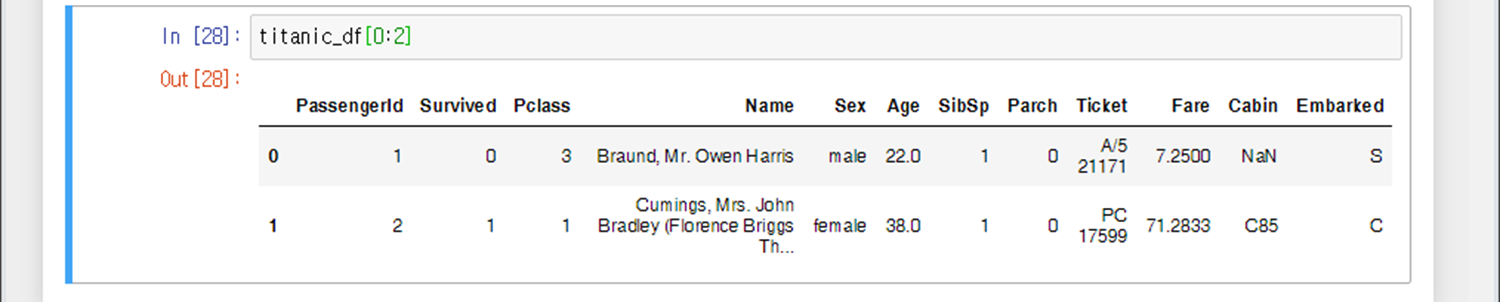
<예시4>
data_df를 만들어서, data_df.iloc[0,0] 즉 0행 0열의 값을 추출했다.

<예시5>
*.iloc함수는 오직 행/열 번호만으로 값 추출이 가능한 함수이다. 0행의 Name 열 전체 또는 One행 0열 전체를 출력하려고 아래와 같이 했으나, 오류가 난다. 이런 경우, 이름기반 인덱싱 함수인 loc 함수를 써야 한다.

<예시6>
팬시 인덱싱과 슬라이싱 인덱싱도 가능하다.

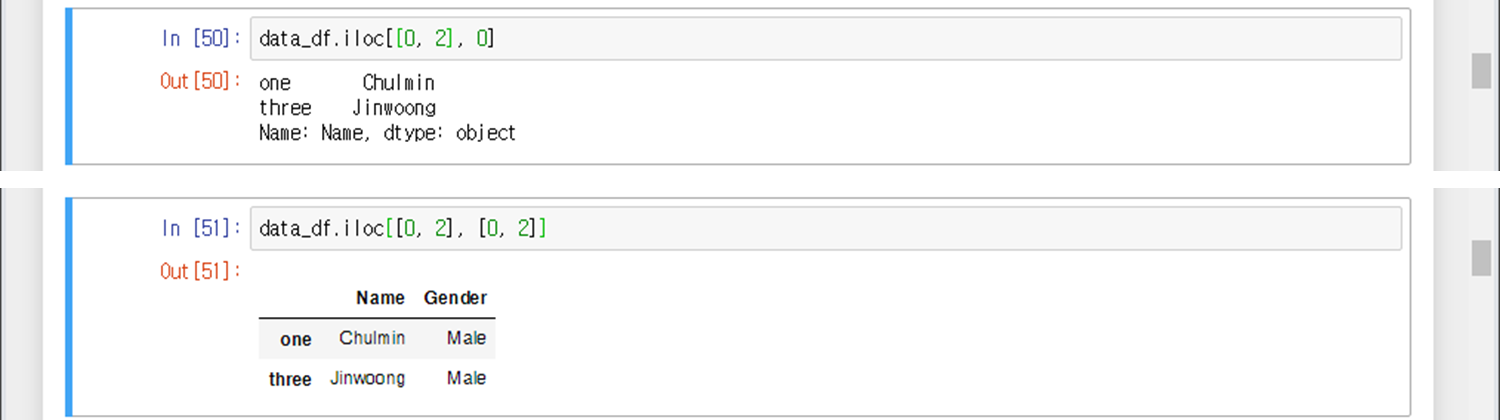

<예시7>
행과 열의 이름을 기반으로 추출하고 싶다면, 이름기반 인덱싱함수인 loc함수를 써야 한다.

<예시8>
행의 경우, 대부분 숫자로 구현되어있다. In [56] 에서는 인덱스를 숫자로 부여하였다. 행번호가 숫자인 경우, In [57]과 같이 행에 숫자를 입력하면 된다. (In [58]에 행번호가 1부터 시작하지만, 0을 입력하니 에러가 난 것을 볼 수 있다.)

<예시9>
iloc 함수와 마찬가지로 당연히 loc 함수도 팬시 인덱싱이 가능하다. 아래와 같이 특정 행/열을 여러개 선택할 수 있다.

<예시10>
당연히 슬라이싱 인덱싱도 가능하다.
다만 주의할 점은 행/열이름이 숫자가 아닌 경우, 시작 ~ 끝-1을 할 수 없으므로 시작 ~ 끝이 범위라는 점이다.

<예시11>
'① 특정 행/열 값 추출하기'의 <예시4>와 동일한 결과를 추출하는데, loc함수를 이용해도 가능하다. (많이 쓰이진 않음)

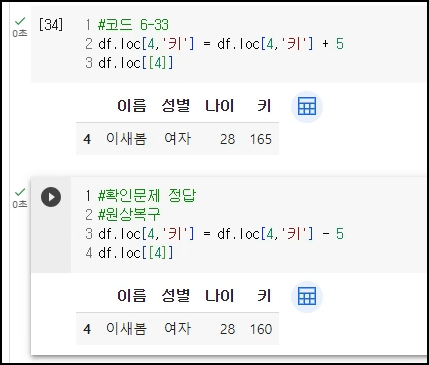
<예시12> - 4번 행의 키를 5cm 더하고 원상복구하기
(L2) 4번 행의 '키'열에 해당하는 값을 5더하라
(L3) 4번 행의 데이터프레임 출력
(아래 소스) 5 더한 부분을 원상복구 수행
<예시14> - 1~3행의 키값을 "모름"으로 변경
(L2) 1~3행의 키 값을 "모름"으로 변경, 여기서 ['모름'] * 3은 곧, ['모름', '모름', '모름']을 의미한다.
(아래 소스코드) 수정한 부분을 원복

③ 특정 숫자/글자가 들어가는 경우 출력
변수=*_df[df['나이'].isin([21, 23])] : 나이가 21세, 23세인 행들을 변수에 저장
df[df['이름'].str.contains('봄')] : 이름에 '봄'이 들어가는 경우 출력
df[df['이름'].str.contains('^봄')] : 이름이 '봄'으로 시작하는 경우 출력
df[df['이름'].str.contains('봄$')] : 이름이 '봄'으로 끝나는 경우 출력
df[df['이름'].str.contains('^.{1}봄')] : 이름의 두 번째 글자가 '봄'인 경우 출력
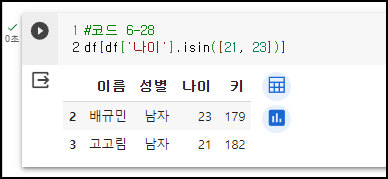
<예시1> - 나이가 21세, 23세인 행들만 출력
<예시2> - contrains 함수를 이용하여 특정 문자열 출력
(코드 6-30) 현재 df 데이터프레임의 현황 출력
(코드 6-31) 이름에 어디든 '현'이 들어가면 출력
(코드 6-32) 이름이 '오'로 시작하면 출력
(코드 6-33) 이름이 '현'으로 끝나면 출력
(코드 6-34) 이름 두 번째 글자(가운데 글자)가 '규'이면 출력

8) 데이터프레임 정렬하기
df.sort_index(axis=0).head( ) : 인덱스 순번 기준으로 오름차순 정렬
변수=*_df.sort_values(by=['열이름'], ascending=True, inplace=False) : 특정 열이름 기준으로 오름차순 정렬하고 원본객체는 수정하지 않음
asending 옵션 : True(기본값, 오름차순 정렬) / False(내림차순 정렬)
inplace 옵션 : False(기본값, 원본객체 수정X) / True (원본객체 수정O)
<예제1> - 인덱스 순번 기준으로 오름차순 값 정렬

<예제3> - 특정 열을 기준으로 값 정렬
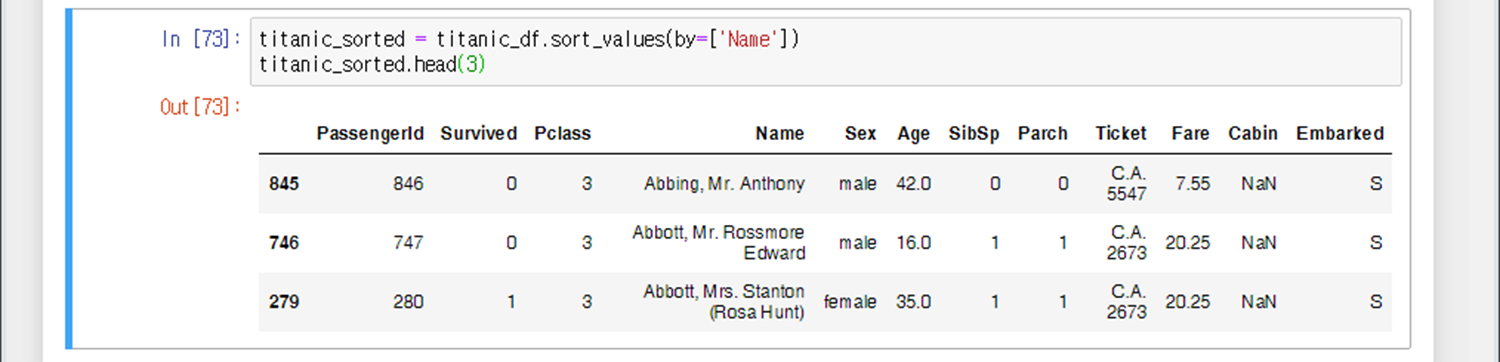
Name을 기준으로 오름차순 정렬한다. ascending과 inplace는 생략하였으므로 기본값으로 설정되어있다.
<예제4> - 2개 열을 기준으로 값 정렬
나이를 기준으로 내림차순 정렬하고, 동등인 경우, 키를 기준으로 내림차순 추가 정렬한다.

<예제5> - 2개 열을 기준으로 값 정렬
먼저 'Pclass' 열을 기준으로 정렬하고 그 다음에 'Name' 열을 기준으로 정렬한다. 먼저 'Pclass' 열에 대한 정렬이 이루어지며, 'Pclass' 값이 동일한 경우 'Name' 열을 기준으로 추가 정렬한다.

9) 데이터프레임의 통계함수(Aggregation 함수)
*_df.min() : *_df 데이터프레임의 각 열당 최소값 리턴
*_df.max() : *_df 데이터프레임의 각 열당 최대값 리턴
*_df.sum() : *_df 데이터프레임의 각 열당 합계 리턴
*_df.count() : *_df 데이터프레임의 각 열당 셀 개수 리턴
*_df.mean() : *_df 데이터프레임의 각 열당 평균값 리턴
*_df.std() : *_df 데이터프레임의 각 열당 표준편차 리턴
*_df.median() : *_df 데이터프레임의 각 열당 중간값 리턴
*_df.agg({'max', 'min', 'median'...}) : *_df 데이터프레임의 각 열당 max, min 등 여러 값들을 출력
*_df.agg({'A':'max', 'B':'min', 'C':'median'...}) : *_df 데이터프레임의 A열은 max, B열은 min 등 딕셔너리포맷으로 각각 다른 값들을 출력
<예시1>
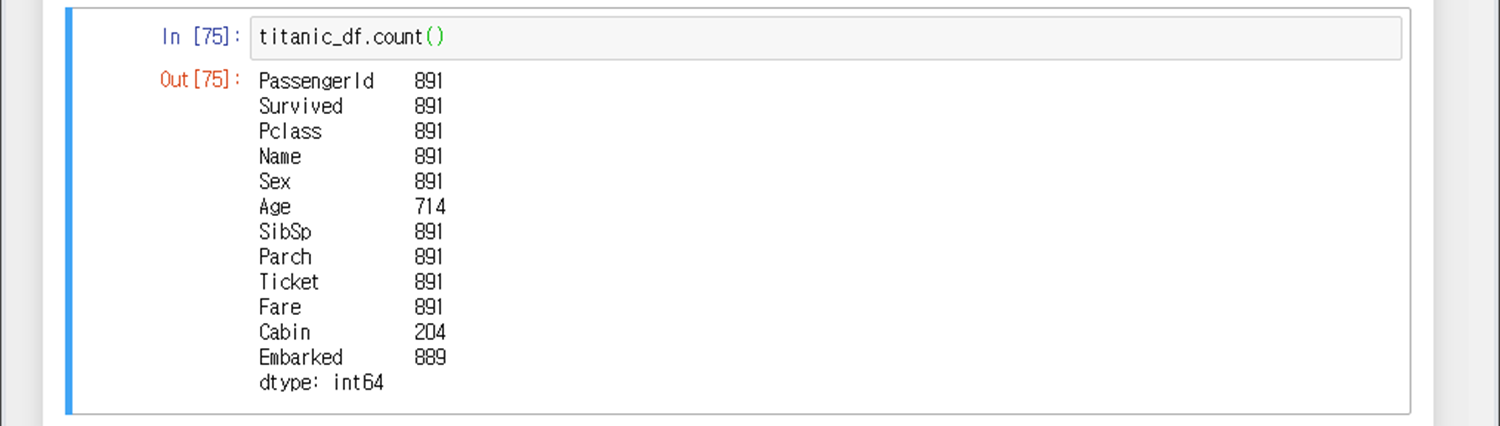
titanic_df 데이터프레임의 각 열당 셀 개수 구하기
<예시2>
titanic_df 데이터프레임의 Age와 Fare의 평균값 구하기

<예시3>
titanic_df 데이터프레임의 모든 열의 max와 min값 구하기
에러가 뜬 이유는 'Cabin'과 'Embarked' 열은 max와 min값을 도출할 수 없어서 에러가 리턴됨. max/min을 구할 수 없는 열은 생략된 채로 출력된다.

<예시4>
titanic_df 데이터프레임의 Age, Fare 열의 max와 min값 구하기

<예시5>
titanic_df 데이터프레임의 Age는 max값을, Fare은 min값 구하기

.
10) 데이터프레임의 그룹함수(groupby 함수)
변수=*_df.groupby(by='컬럼명').통계함수() : *_df 데이터프레임의 특정 컬럼의 값들을 그룹화하여 '행'으로 표현하여 변수에 대입
변수=*_df.groupby(by=['물건'], as_index=False)['가격'].통계함수() : *_df 데이터프레임의 물건 별 가격을 '열'로 표현하여 변수에 대입 (as_index=False는 인덱스 발번한다는 뜻이고, True는 발번 X)
★ 주의 ★
groupby 함수는 끝에 통계함수를 쓰지 않으면 자료형을 리턴한다.
예)
<pandas.core.groupby.generic.DataFrameGroupBy object at 0x000001CF92D72D10>
원하는 값을 보려면 반드시 뒤에 통계함수()를 써줘야 한다. 값을 보기 위한 것이라면 max나 min 함수를 쓰는 것을 추천한다.
<예시1>
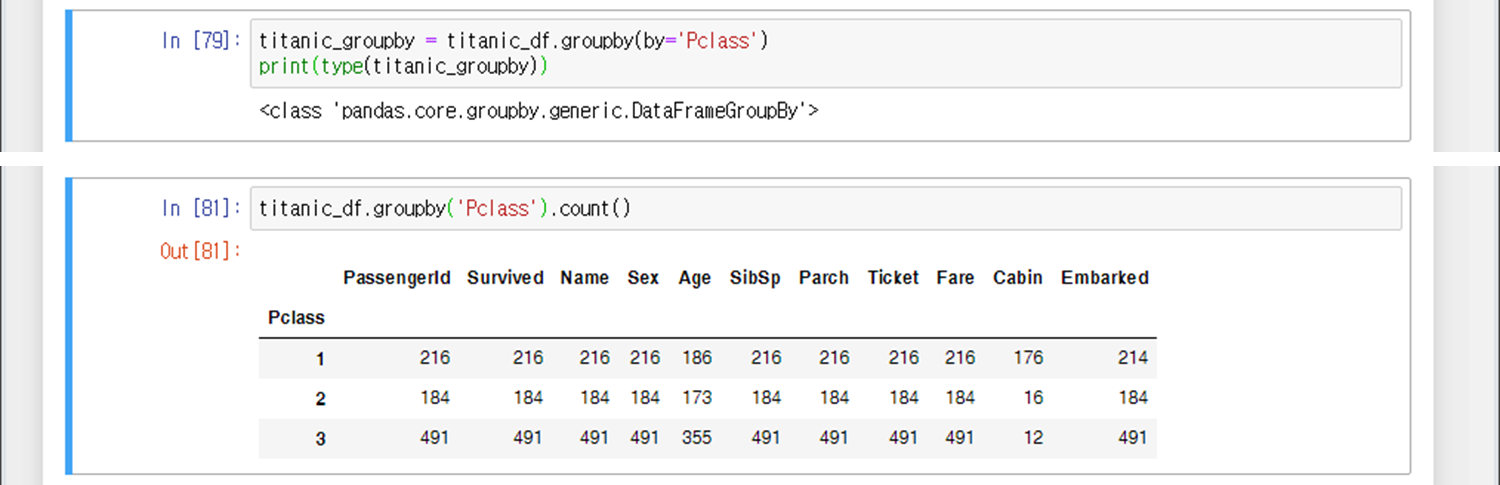
In [79] : 데이터프레임의 Pclass열을 groupby 함수로 만든 변수는 DataFrameGroupBy라는 자료형으로 정의된다.
In [81] : Groupby 함수를 통해 Pclass열을 그룹화하여 행으로 표현한 후 나머지 열들의 셀 개수를 카운트한다.
<예시2>
Pclass 열을 그룹화하여 행으로 표현하고, PassengerId와 Survived 열의 개수만 출력

<예시3>
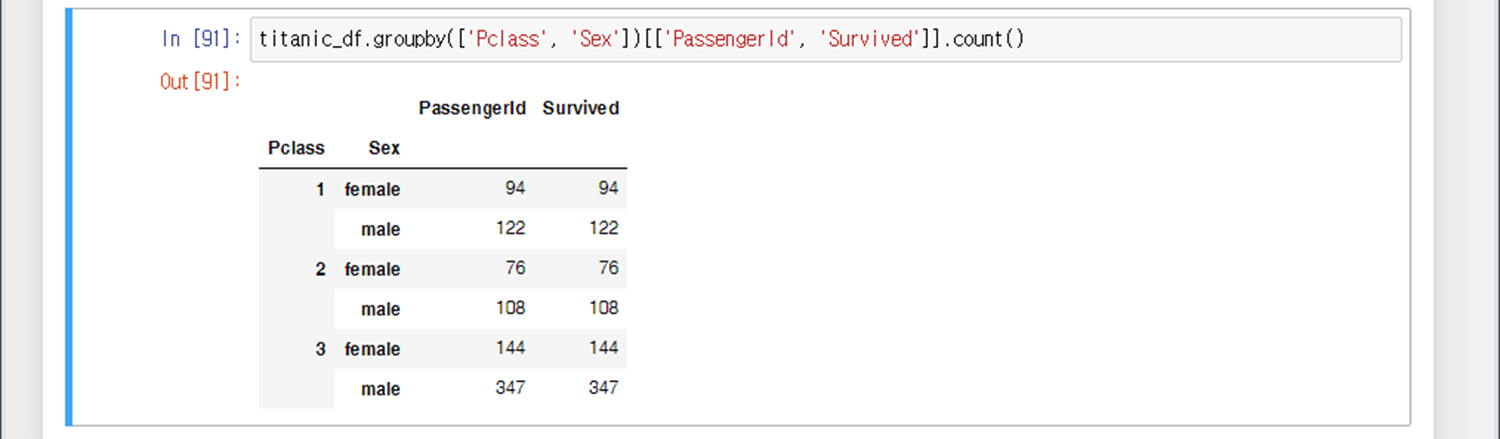
Pclass, Sex 열을 그룹화하여 행으로 표현하고, 나머지 모든 열의 개수만 출력

<예시4>
Pclass, Sex 열을 그룹화하여 행으로 표현하고, PassengerId와 Survived 열의 개수만 출력
<예시5>
Pclass 열을 그룹화하여 행으로 표현하고, Age 열의 최대/최소값 출력

<예시6>
Pclass 열을 그룹화하여 행으로 표현하고, Age열과 Fare열의 최대/최소값 출력

<예시7>
Pclass 열을 그룹화하여 행으로 표현하고, Age열은 max값을, SibSp열은 sum값을, Fare열은 평균값을 출력

<예시8>
성별을 남자, 여자로 그룹지어서 평균 키와 키의 표준편차를 구한 데이터프레임 생성

<예시9>
강의실 별 이용 시간수를 출력, 별도의 index를 발번(as_index=False)

11) 결손 데이터(NaN값)
*_df.isna() : *_df 데이터프레임의 NaN 여부 확인 (True인 경우, NaN값 존재)
*_df.isna().sum() : *_df 데이터프레임의 NaN 개수 출력
*_df.isna() : *_df 데이터프레임의 NaN 여부 확인 (True인 경우, NaN값 존재)
*_df ['열이름_a'] = *_df['열이름'].fillna('~~~') : *_df 데이터프레임의 특정 열의 NaN이 존재하는 경우, 맨 마지막 열에 열이름_a를 추가하여 NaN→~~~로 변경한 열 추가
*_df ['열이름'] = *_df['열이름'].fillna('~~~') : *_df 데이터프레임의 특정 열의 NaN이 존재하는 경우, 해당 열의 NaN→~~~로 값 변경
*_df['열이름'].fillna('~~~', inplace=True) : *_df 데이터프레임의 특정 열의 NaN이 존재하는 경우, 해당 열의 NaN→~~~로 값 변경 ( *_df ['열이름'] = *_df['열이름'].fillna('~~~') 명령어와 동일한 결과 리턴)
<예시1>
titanic_df 데이터프레임의 NaN값 유무 확인 (Cabin에서 True보임에 따라 Cabin 열에 NaN값이 존재한다.)

<예시2>
각 열마다 NaN값이 몇개 존재하는지 확인

<예시3>
titanic_df 데이터프레임의 Cabin 열에 NaN값이 있으면 맨 마지막 열에 Cabin_Updated 열을 추가하여 NaN → C000으로 변경

<예시4>
In [122] : titanic_df 데이터프레임의 Cabin 열에 NaN값이 있으면 해당 열을 NaN → C000으로 변경
In [123] : titanic_df 데이터프레임의 Cabin 열에 NaN값이 있으면 해당 열을 NaN → C000으로 변경 (In [122]와 동일한 결과)


12) 람다표현식으로 함수생성
변수명= lambda x: 수식
print(변수명(x))
:: 간단한 수식을 람다표현식으로 함수 생성 후, 그 결과를 출력
list(map(lambda x: 수식, [리스트 값])) : 리스트 값에 람다표현식으로 생성한 함수를 모두 적용
*_df['열이름_a']=*_df['열이름'].apply(lambda x: 수식) : *_df 데이터프레임에 특정 열의 값을 람다표현식의 함수를 적용하여 나온 값들을 마지막 열(열이름_a)에 저장
*_df['열이름_a']=*_df['열이름'].apply(lambda x: 'A' if x>5 else 'B') : *_df 데이터프레임에 특정 열의 값을 5보다 크면 A, 작으면 B로 리턴하여 마지막 열(열이름_a)에 저장
<예시1>
람다표현식으로 lambda_square 함수명으로 생성. 3을 인자로 넣어 9를 반환받음

<예시2>
[1,2,3] 리스트를 생성하고, 모든 리스트 값에 람다표현식을 적용하여 [1,2,3] → [1,4,9]를 반환받음

<예시3>
titanic_df 데이터 프레임의 Name 열의 각 항목들의 문자열 길이를 구하는 람다표현식을 적용하여 그 결과를 Name_len열에 저장한다. (Name_len 열은 새로 생성된 열임)

<예시4>
Age 열의 값이 15이하이면 Child, 초과이면 Adult로 리턴하여 Child_Adult(마지막열)에 저장

<예시5>
(L1) : Age 열의 값이 15이하이면 Child, 60이상이면 Elderly, 그 사이면 Adult로 리턴하여 Age_cat(마지막열)에 저장
(L2) : Child, Adult, Elderly로 구분된 Age_cat 열의 각각 개수를 출력

<예시6>
나이별로 그 결과값을 리턴해주는 get_category 함수를 생성하여 람다표현식의 수식부분에 get_category함수를 적용하였음.
수식을 정리하면, 람다표현식(get_category함수(x)) 형태이다.
get_category함수에서 반환된 값들을 Age_cat 열에 저장

<Practice> :: 강의 시간표 분석

위의 표의 데이터로 판다스 데이터프레임을 생성하고 시간표 데이터를 분석해 봅시다.
1. 위 표를 참고하여 열 이름을 'col_names'로, 각 행의 정보를 'list1'으로 리스트 정의한다.
2. 1번에서 만든 'col_names'와 'list1'을 이용하여 데이터프레임 'df'을 생성하고 이를 'timetable.csv' 파일로 저장한다. (헤더,인덱스,인코딩타입은 각각 True, False, utf-8로 저장)
3. 'timetable.csv' 파일을 불러와서 'df2'에 저장하고, 마지막 열에 '교수' 열을 추가하고 ['김예희', '오정현', '인세훈', '이새봄', '배유진', '이가원']을 배정한다.
4. 강의실을 기준으로 그룹화하여 max()함수를 통해 강의실 최대 이용시간 현황을 'max_hour'에 저장하고 출력한다. (별도의 인덱스를 발번 할 것)
1.열 이름과 시간표 데이터를 리스트로 저장.
col_names = ['과목번호', '과목명', '강의실', '시간수']
list1 = list([['C1', '인공지능개론', 'R1', 3],
['C2', '웃음치료', 'R2', 2],
['C3', '경영학', 'R3', 3],
['C4', '3D디자인', 'R4', 4],
['C5', '스포츠경영', 'R2', 2],
['C6', '예술의 세계', 'R3', 1]
])
2. 시간표 데이터를 데이터프레임 객체 df로 변환하여 CSV 파일로 저장.
import pandas as pd
df = pd.DataFrame(list1, columns=col_names)
df.to_csv('./timetable.csv', header=True, index=False, encoding='utf-8')
df2 = pd.read_csv('./timetable.csv', sep=',')
df2['교수'] = ['김예희', '오정현', '인세훈', '이새봄', '배유진', '이가원']
df2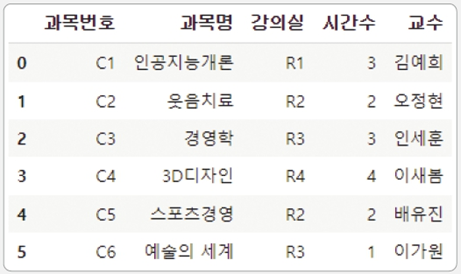
4. 강의실을 기준으로 그룹화하여 max( ) 함수로 최대 시간 수를 구하기.
max_hour = df2.groupby(by=['강의실'], as_index=False)['시간수'].max()
max_hour
'IT > 머신러닝 & 인공지능 & 데이터사이언스' 카테고리의 다른 글
| [파이썬 기본 3] 머신러닝 필수 라이브러리 :: 넘파이 총정리 (1) | 2023.10.05 |
|---|---|
| [파이썬 기본 2] 조건문(If/else/elif문), 반복문(while문/for문) (0) | 2023.10.05 |
| [파이썬 기본 1-2] 자료형(문자열/콜렉션), 함수 정의 (1) | 2023.10.05 |
| [파이썬 기본 1-1] 초기 세팅 및 변수, 연산자, sep, input, 형변환, eval() (0) | 2023.09.25 |